Agentic AI Work Flow In Cybersecurity
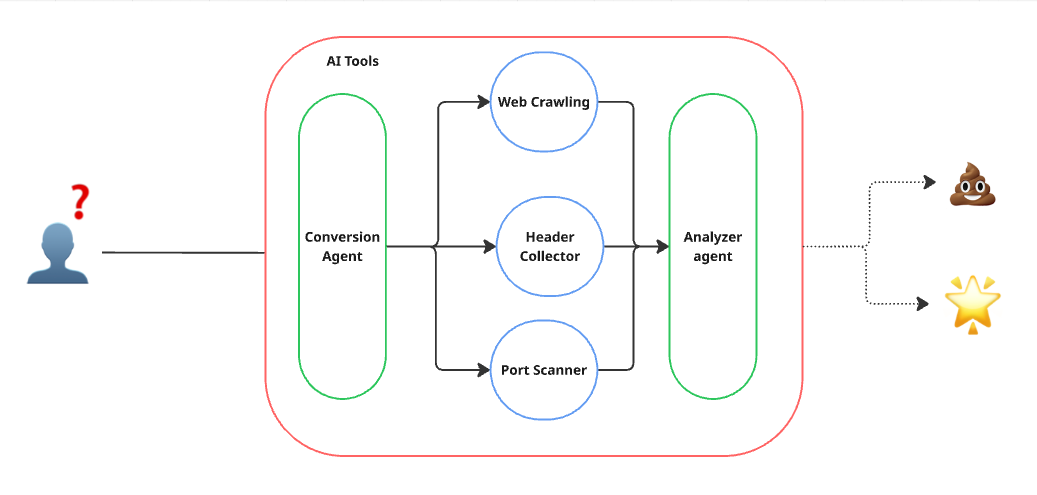
Agentic AI Work Flow In Cybersecurity
ในปี 2025 เด็ก Generation Alpha เติบโตมาพร้อมกับเทคโนโลยีที่คาดว่าจะเปลี่ยนแปลงวิธีการทำงานในหลายภาคส่วนอย่างก้าวกระโดด นั่นคือ AI (artificial intelligence) โดยเฉพาะ gen-AI (Generative artificial intelligence) และ Agentic AI ที่สามารถทำงานร่วมกัน แบ่งหน้าที่ และตรวจสอบข้อมูลกันเองได้ เพียงแค่ได้ยินแนวคิด (concept) นี้ก็รู้สึกว่ามันเจ๋งมากแล้ว แต่ถ้าเราฝันว่าจะให้ AI ทำงานแทนเราทั้งหมด ก็คงเหมือนวิชาแยกเงาพันร่างนั่นแหละ 555
ในบทความนี้เราจะมาพูดถึงการใช้งาน Agentic AI ในงาน cyber security กันนะครับ (จะลองไปด้วยกันเพราะผมเองก็ไม่เคยลองเหมือนกัน 555) โดยไม่ได้เน้นสอน dev หรือ cyber security แต่จะแชร์ไอเดียกันมากกว่า
Agentic AI คืออะไร
Agentic AI คือระบบ AI ที่สามารถทำงานได้อย่างอิสระและมีเป้าหมายชัดเจน โดยมีความสามารถในการวางแผน ตัดสินใจ และดำเนินการเพื่อบรรลุเป้าหมายที่กำหนดไว้ ต่างจาก AI ทั่วไปที่มักจะตอบสนองต่อคำสั่งแบบตรงไปตรงมา Agentic AI จะสามารถทำงานร่วมกับ AI ตัวอื่นๆ แบ่งงานกันทำ และปรับเปลี่ยนแผนการทำงานได้ตามสถานการณ์
Scope of Task
ก่อนที่เราจะไปทำ agent เรามาดูก่อนว่าจะให้มันช่วยงานอะไรเราได้บ้าง โดยยกตัวอย่างงานที่คิดว่าทำได้
- ช่วยเก็บ information
- ช่วยวิเคราะห์ attack surface ที่คาดว่าจะโดนโจมตี
- automate exploit
- เขียน report ?
จากงานที่เราเลือกมาข้างต้น ที่ง่ายที่สุดคงเป็นการช่วยเก็บ information เป้าหมาย
ต่อมาเราต้องแยกประเภท information ที่อยากจะเก็บก่อน (ยกตัวอย่าง web application)
- URL and Path
- Service Port และ Version
- HTTP Security header
- Java Library และ Version
URL and Path
ในกระบวนการเก็บรวบรวม URL และ Path ต่างๆ ในเว็บไซต์ เราจำเป็นต้องใช้เทคนิคการทำ web crawling และ directory brute force
Web crawling คือกระบวนการอัตโนมัติในการค้นหาและรวบรวมข้อมูลจากเว็บไซต์
โดยระบบจะเข้าไปสำรวจและเก็บข้อมูลจากหน้าเว็บต่างๆ อย่างเป็นระบบ
ซึ่งในบริบทนี้ใช้สำหรับการรวบรวม URL และ Path ของเว็บแอปพลิเคชัน
เริ่มจากที่เราทำ Web crawling ง่ายๆ ผ่าน code python ดังนี้
import requests
from bs4 import BeautifulSoup
import urllib.parse
import time
import csv
from collections import deque
import os
class WebCrawler:
def __init__(self, starting_url, domain_restriction=None, delay=1, max_pages=100):
"""
Initialize the web crawler
Args:
starting_url (str): The URL to start crawling from
domain_restriction (str, optional): Restrict crawling to this domain only
delay (int, optional): Delay between requests in seconds
max_pages (int, optional): Maximum number of pages to crawl
"""
self.starting_url = starting_url
self.visited_urls = set()
self.urls_to_visit = deque([starting_url])
self.delay = delay
self.max_pages = max_pages
# Extract domain from starting URL if not provided
if domain_restriction is None:
parsed_url = urllib.parse.urlparse(starting_url)
self.domain_restriction = parsed_url.netloc
else:
self.domain_restriction = domain_restriction
self.data = []
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def is_valid_url(self, url):
"""Check if URL should be crawled"""
parsed_url = urllib.parse.urlparse(url)
# Check if URL is within allowed domain
if self.domain_restriction and parsed_url.netloc != self.domain_restriction:
return False
# Skip non-http(s) URLs
if parsed_url.scheme not in ['http', 'https']:
return False
# Skip already visited URLs
if url in self.visited_urls:
return False
return True
def extract_links(self, soup, base_url):
"""Extract all links from a page"""
links = []
for link in soup.find_all('a', href=True):
href = link['href']
# Convert relative URLs to absolute URLs
absolute_url = urllib.parse.urljoin(base_url, href)
# Normalize the URL
absolute_url = urllib.parse.urldefrag(absolute_url)[0] # Remove fragments
if self.is_valid_url(absolute_url):
links.append(absolute_url)
return links
def extract_data(self, soup, url):
"""
Extract relevant data from the page
Override this method in subclasses to customize data extraction
"""
title = soup.title.text.strip() if soup.title else "No Title"
# Example: extract all paragraph text
paragraphs = [p.text.strip() for p in soup.find_all('p')]
# Example: extract metadata
meta_description = ""
meta_tag = soup.find("meta", attrs={"name": "description"})
if meta_tag and "content" in meta_tag.attrs:
meta_description = meta_tag["content"]
return {
"url": url,
"title": title,
"meta_description": meta_description,
"paragraph_count": len(paragraphs),
"first_paragraph": paragraphs[0] if paragraphs else ""
}
def crawl(self):
"""Start the crawling process"""
count = 0
while self.urls_to_visit and count < self.max_pages:
# Get the next URL to visit
url = self.urls_to_visit.popleft()
# Skip if already visited
if url in self.visited_urls:
continue
print(f"Crawling: {url}")
try:
# Make the request
response = requests.get(url, headers=self.headers, timeout=10)
# Check if request was successful
if response.status_code == 200:
# Mark as visited
self.visited_urls.add(url)
count += 1
# Parse HTML
soup = BeautifulSoup(response.text, 'html.parser')
# Extract data
page_data = self.extract_data(soup, url)
self.data.append(page_data)
# Extract links and add to queue
links = self.extract_links(soup, url)
for link in links:
if link not in self.visited_urls:
self.urls_to_visit.append(link)
# Respect robots.txt by adding delay
time.sleep(self.delay)
else:
print(f"Failed to retrieve {url}: Status code {response.status_code}")
except Exception as e:
print(f"Error crawling {url}: {str(e)}")
print(f"Crawling complete. Visited {len(self.visited_urls)} pages.")
def save_data_to_csv(self, filename="crawl_results.csv"):
"""Save the extracted data to a CSV file"""
if not self.data:
print("No data to save.")
return
# Get all unique keys from all dictionaries
fieldnames = set()
for item in self.data:
fieldnames.update(item.keys())
with open(filename, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(self.data)
print(f"Data saved to {filename}")
# Example usage
if __name__ == "__main__":
# Create a custom crawler class by extending WebCrawler
class NewsCrawler(WebCrawler):
def extract_data(self, soup, url):
"""Custom data extraction for news sites"""
title = soup.title.text.strip() if soup.title else "No Title"
# Find article content
article = soup.find('article')
content = ""
if article:
paragraphs = article.find_all('p')
content = " ".join([p.text.strip() for p in paragraphs])
# Try to find publication date
date_tag = soup.find("meta", attrs={"property": "article:published_time"})
date = date_tag["content"] if date_tag and "content" in date_tag.attrs else "Unknown"
return {
"url": url,
"title": title,
"publication_date": date,Í
"content_preview": content[:200] + "..." if content else "",
"word_count": len(content.split()) if content else 0
}
# Create and run the crawler
# Replace with the website you want to crawl
crawler = NewsCrawler(
starting_url="https://example.com",
domain_restriction="example.com",
delay=2, # Be respectful with delay between requests
max_pages=20 # Limit number of pages to crawl
)
crawler.crawl()
crawler.save_data_to_csv("news_results.csv")
นอกจากนี้เรายังใช้งาน directory brute force ผ่านเครื่องมือ dirsearch (https://github.com/maurosoria/dirsearch)
ซึ่งเราจะทำการออกแบบประมาณนี้
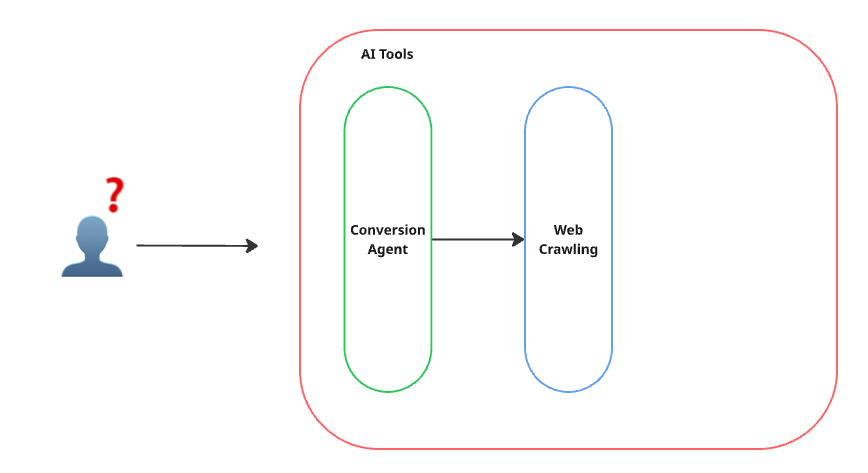
หลังจากได้เครื่องมือทั้ง 2 อย่างแล้ว ถึงเวลาที่เราจะเอาไปเชื่อมต่อกับ AI
สำหรับการทำ Agentic AI ผมเลือกใช้ไลบรารี pydantic_ai ที่รองรับ Gemini และใช้งานง่าย
มาเริ่มต้นเขียน agent กันดูครับ
และเพิ่มในส่วน dirsearch เพื่อทำ directory brute force
ต่อมาเราจะทดสอบเรียกใช้งาน class ที่สร้างขึ้นโดยทดสอบกับเว็บไซต์ https://incognitolab.com
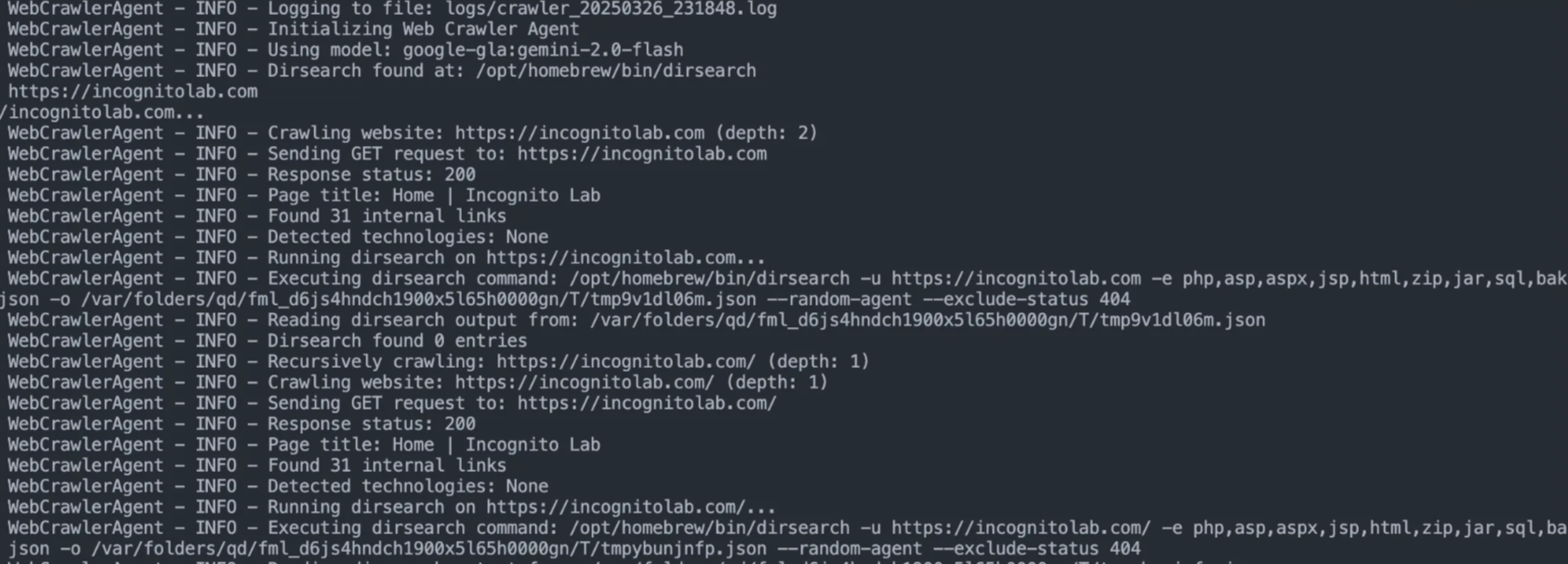
ดูดีใช้ได้เลย ต่อไปเรามาพัฒนา tool ของเราให้มีความสามารถมากขึ้นด้วยการเพิ่ม feature ดังนี้
- เก็บข้อมูล HTTP security header
- เก็บข้อมูล Service port ที่เปิดใช้งานและเวอร์ชันของแต่ละบริการ
- รวบรวมและวิเคราะห์ข้อมูลทั้งหมดเพื่อค้นหาช่องโหว่ที่อาจเกิดขึ้น
Service Port, Service Version และ HTTP Security Header
เมื่อเราออกแบบโครงสร้าง ก็น่าจะได้หน้าตาประมาณนี้ แม้ว่าเรายังไม่รู้ว่าผลลัพธ์จริงจะออกมาเป็นอย่างไร แต่เราจะกำหนดให้แสดงผลเป็น HTML ที่สวยงามไว้ก่อน 555
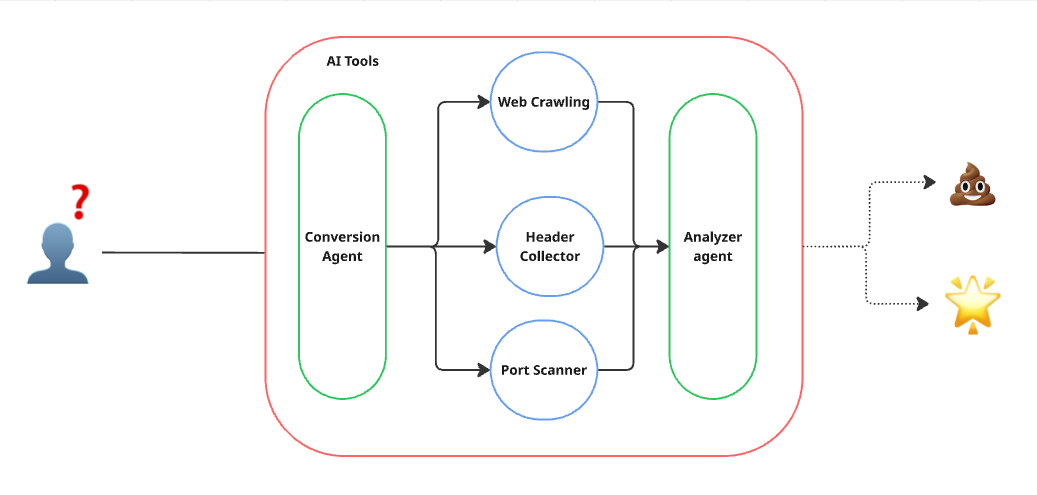
โดยโค้ดของ agent ที่เพิ่มเข้ามาจะเป็นดังนี้
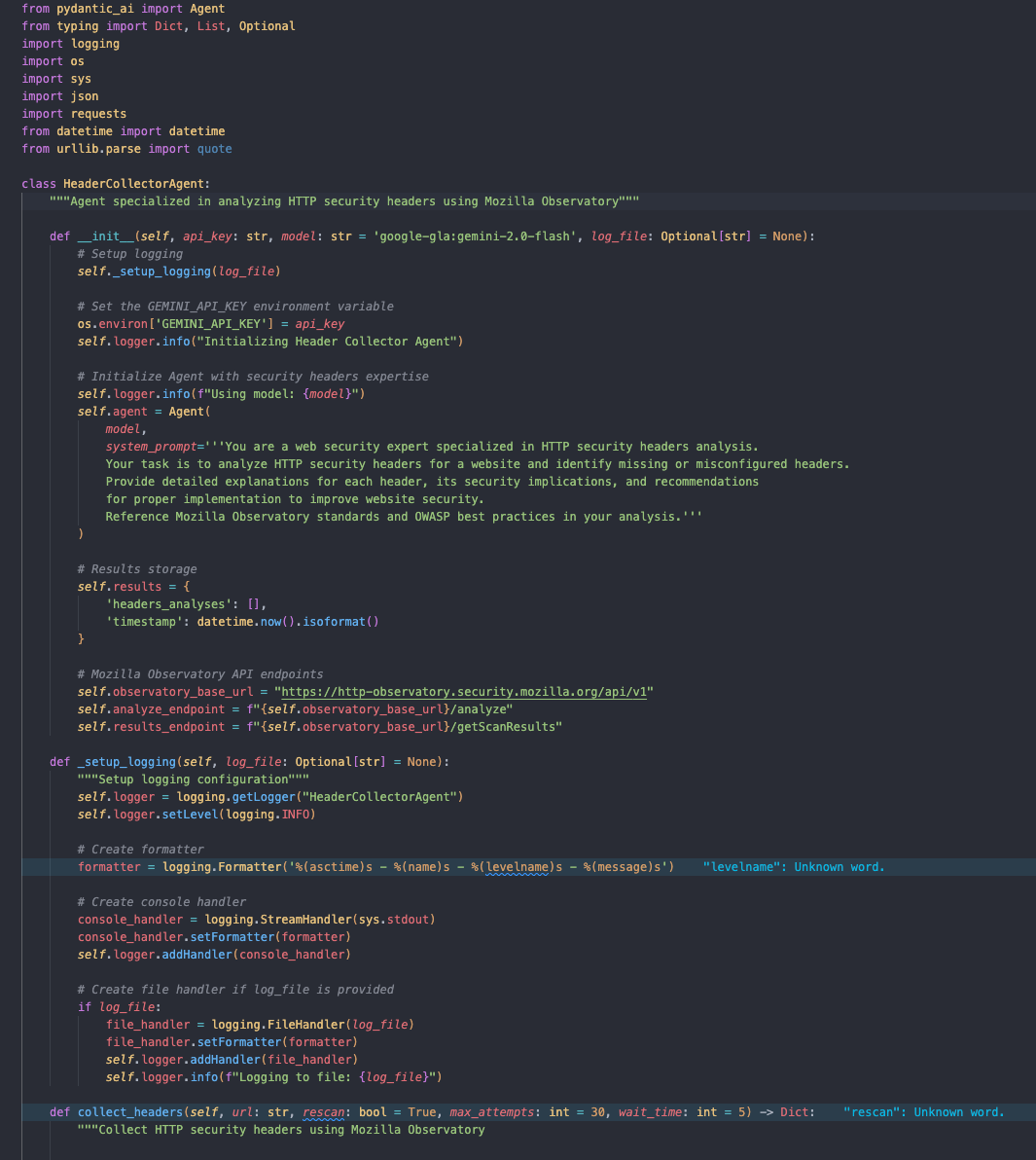
Header Collector
ในส่วนนี้จะทำการเรียกใช้งาน service HTTP security header จากเว็บไซต์พันธมิตรของเราคือ https://hs.iamthana.com/ โดยมีตัวอย่างการตรวจสอบ header ดังนี้
ตัวอย่างการเรียกใช้งาน: https://developer.mozilla.org/en-US/observatory
ผลลัพธ์
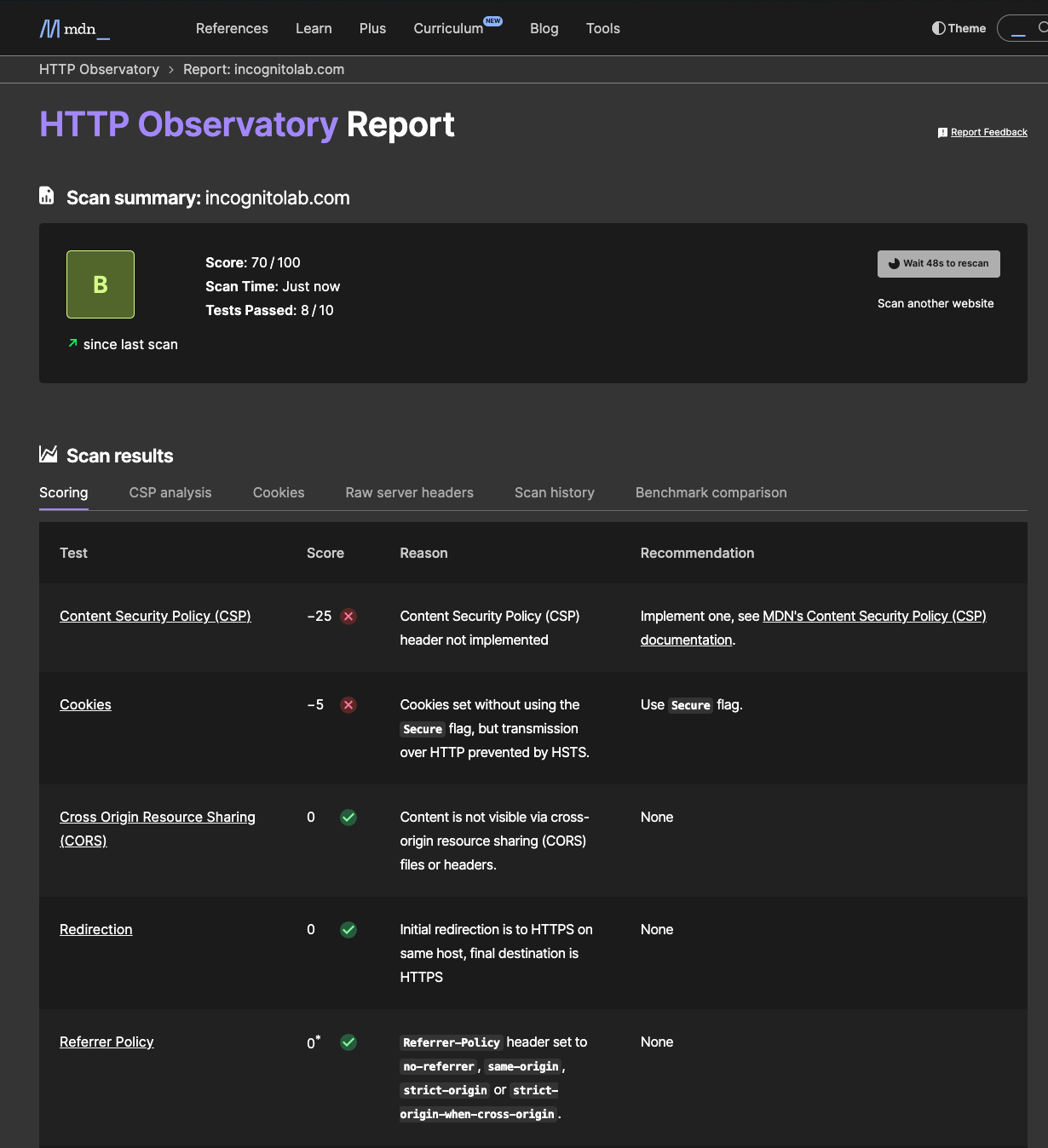
คร่าวนี้มาผนวกรวมกับ agent ของเรา
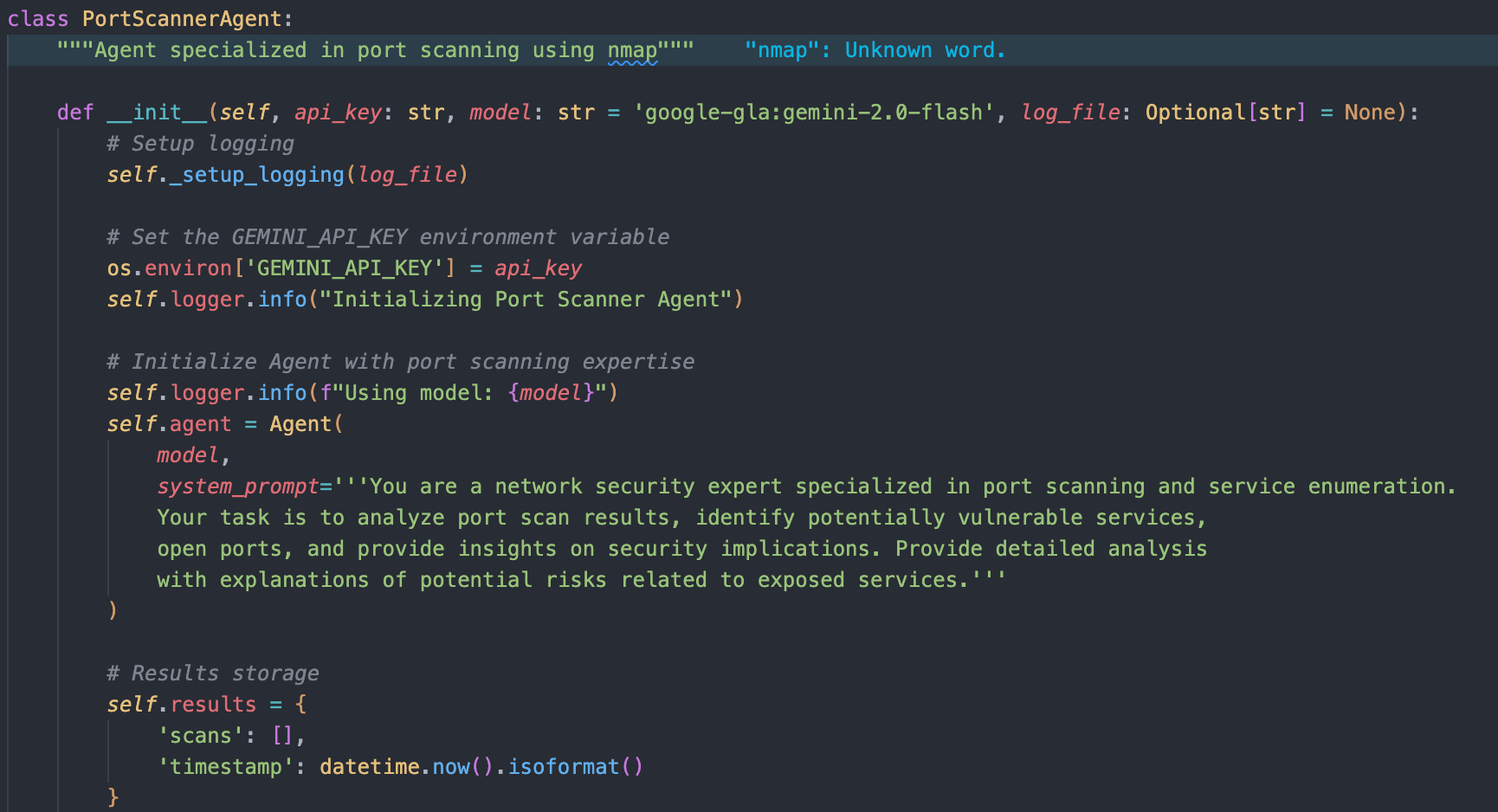
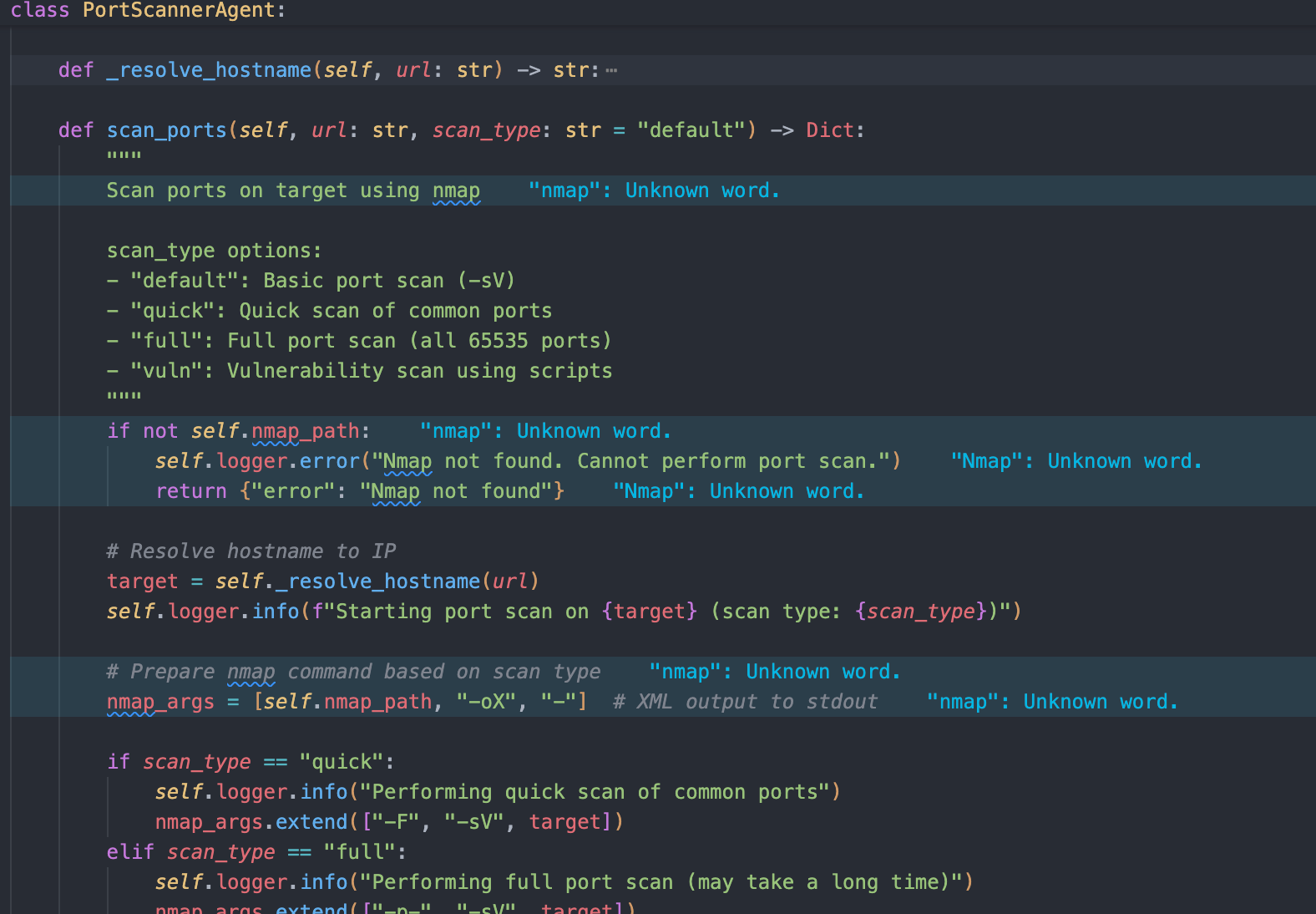
Service Port และ Service Version
สำหรับการตรวจสอบ Service Port และ Service Version เราสามารถใช้งาน nmap scan
ซึ่งเป็นเครื่องมือที่ออกแบบมาเพื่องานนี้โดยเฉพาะ เราจึงสามารถผนวกเข้ากับ agent ได้ดังนี้
Analyzer Agent
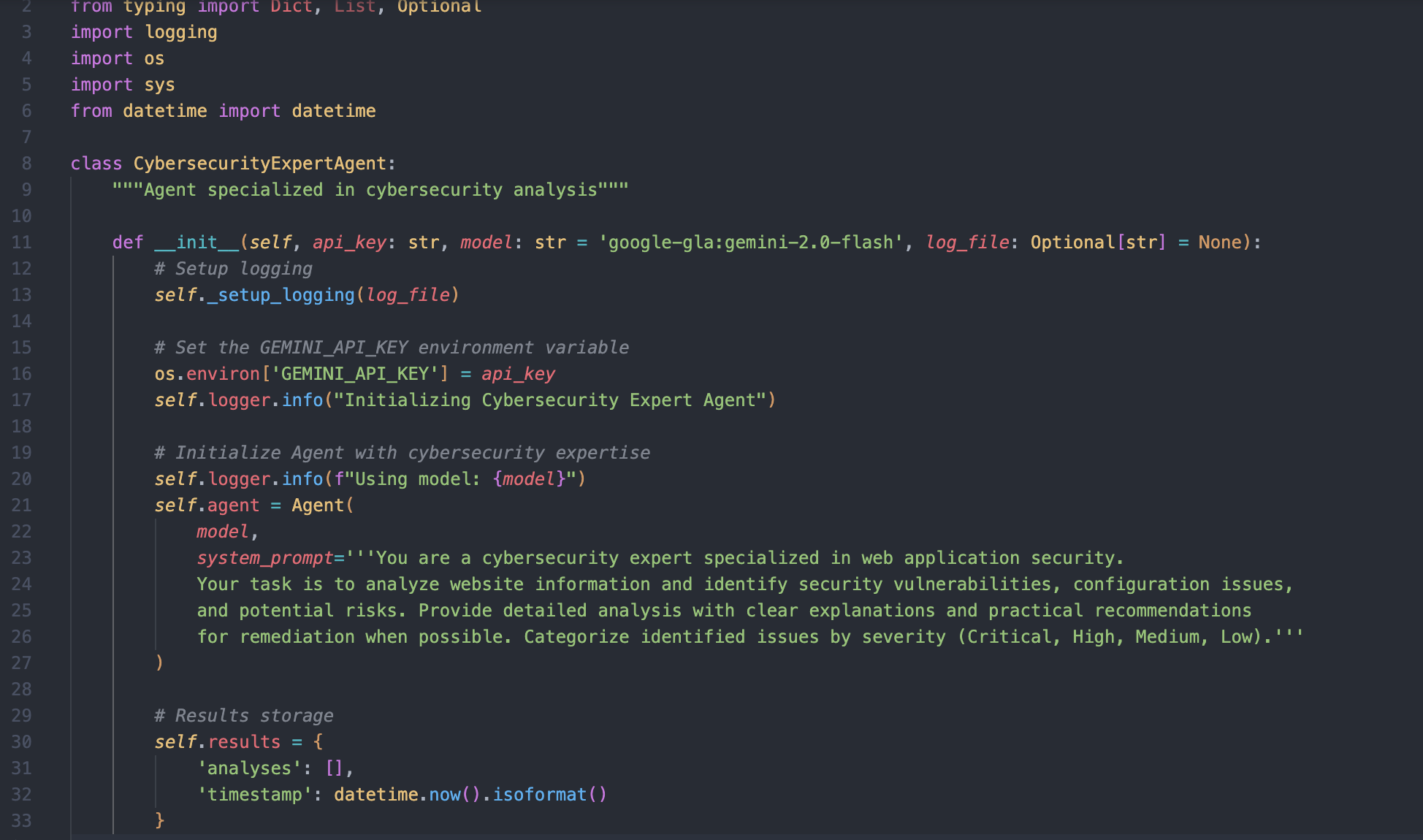
ในส่วนนี้เราจะใช้ข้อมูลจากส่วนก่อนหน้ามาให้ AI วิเคราะห์ทั้งหมด เพื่อค้นหา attack surface และ potential vulnerability ที่อาจเกิดขึ้น เราไม่มีทางรู้เลยว่าผลลัพธ์ที่ได้จะออกมาแย่มากหรือจะออกมาดีเยี่ยม โดยโค้ดส่วนใหญ่จะประกอบไปด้วย
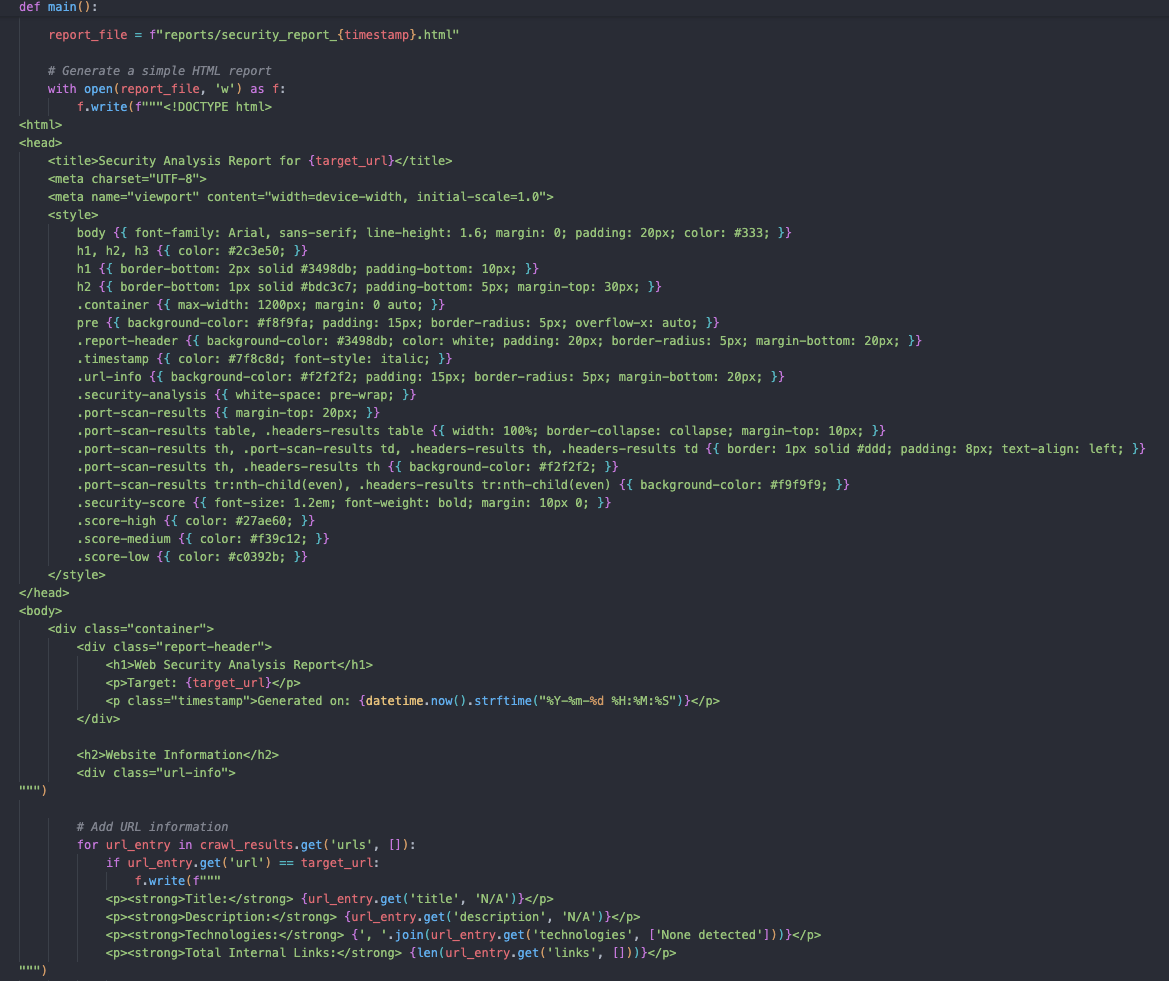
และส่วน export HTML
Test Phase
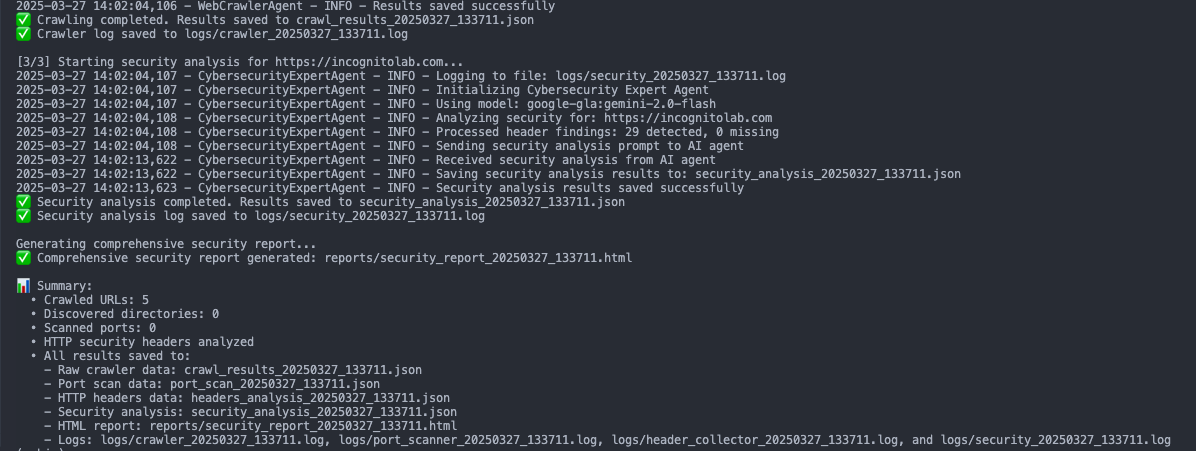
หลังจากเตรียมทุกอย่างเรียบร้อยแล้ว ถึงเวลาทดสอบกัน จากผลลัพธ์ที่ทดลองพบว่าสามารถ run agent ในการรวบรวมข้อมูลได้ตามที่ต้องการ
Review Phase
เมื่อเรามาดูข้อมูลวิเคราะห์ที่ได้จาก Analyzer Agent แล้วพบว่าผลลัพธ์ที่ได้ยังไม่น่าพอใจเท่าที่ควร

ในส่วนการวิเคราะห์ HTTP Security Header นั้น สามารถระบุผลกระทบด้านความปลอดภัยได้ดี แต่คำแนะนำในการแก้ไขยังขาดความชัดเจนและไม่สามารถนำไปปฏิบัติได้ทันที

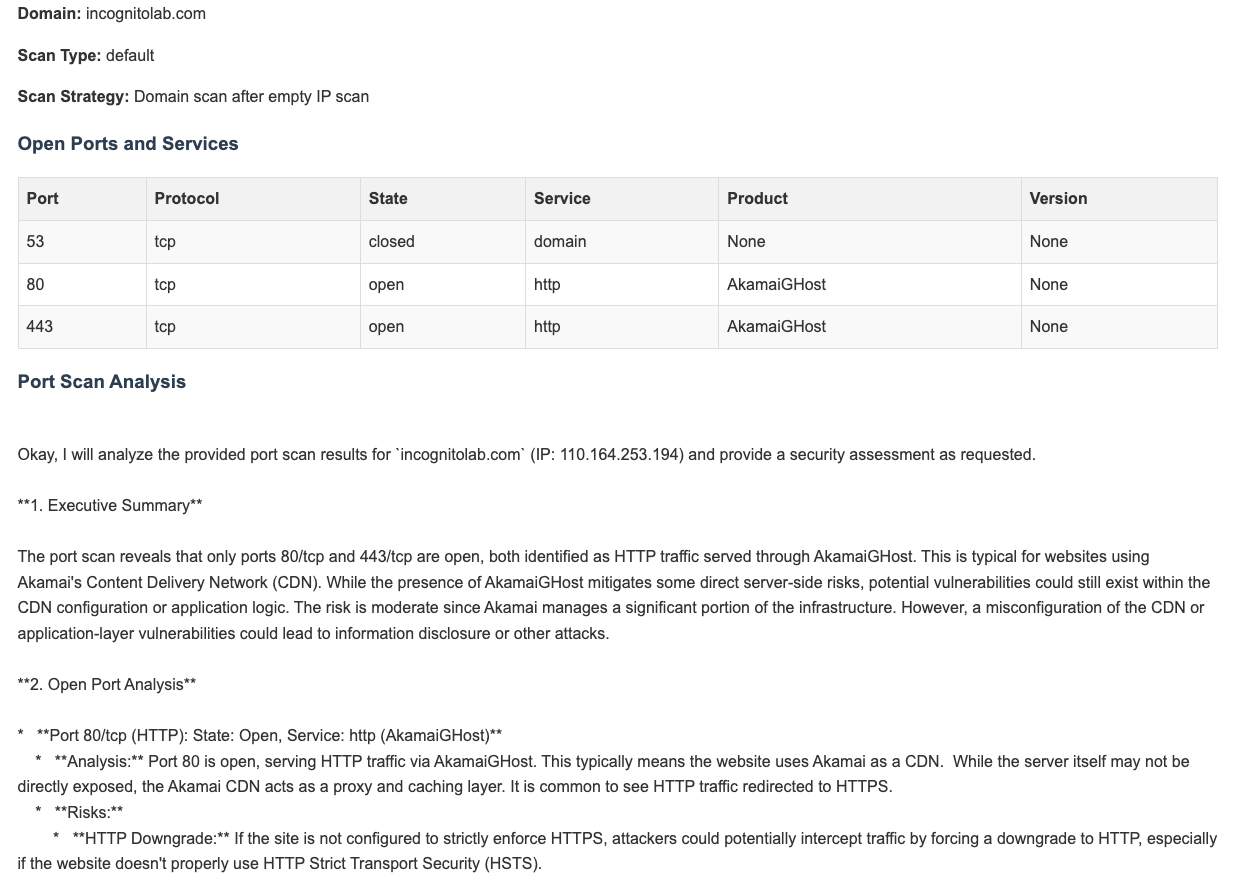
ในส่วนของ port scan พบว่า agent สามารถตรวจพบ service port เว็บเซิร์ฟเวอร์กำลังทำงานอยู่ได้
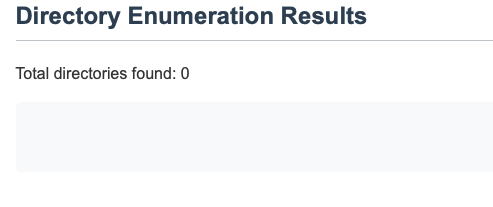
เมื่อทำการตรวจสอบในส่วนของ directories พบว่าไม่สามารถค้นพบ directories ใดๆ จากการใช้ dirsearch
พบเจอแต่ internal link จากการทำ web crawling เท่านั้น

และบทสรุปส่งท้ายที่ได้พบว่า Analyzer Agent สามารถวิเคราะห์ข้อมูลทั้งหมดและเขียนสรุปในมุมมองด้าน cybersecurity ได้ดี อ่านเข้าใจง่าย แต่ยังมีข้อบกพร่องในการประเมินค่า severity score

Optimize phase
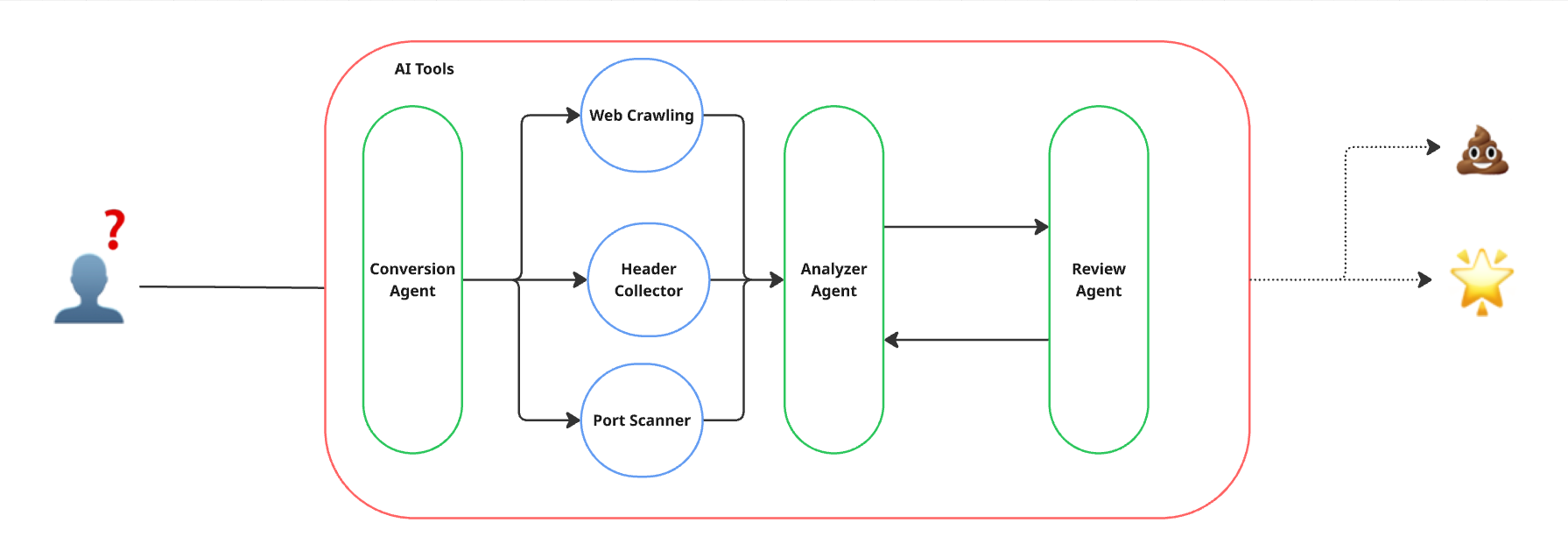
จากผลลัพธ์ที่ได้รับมา เราทำการปรับปรุง 4 อย่างดังนี้
- แก้ไขให้นำ URL internal link มารวมในการค้นหาไดเรกทอรี
- เพิ่ม agent ให้ตรวจสอบผลจาก Analyzer Agent อีกครั้ง หากไม่ถูกต้องให้วิเคราะห์ใหม่
- ใช้ CVSS score ในการประเมินระดับความรุนแรง
จากการปรับปรุงดังกล่าว คาดว่าจะได้ผลลัพธ์ที่ดีขึ้น
ลองทำการทดสอบที่ Inconitolab อีกที
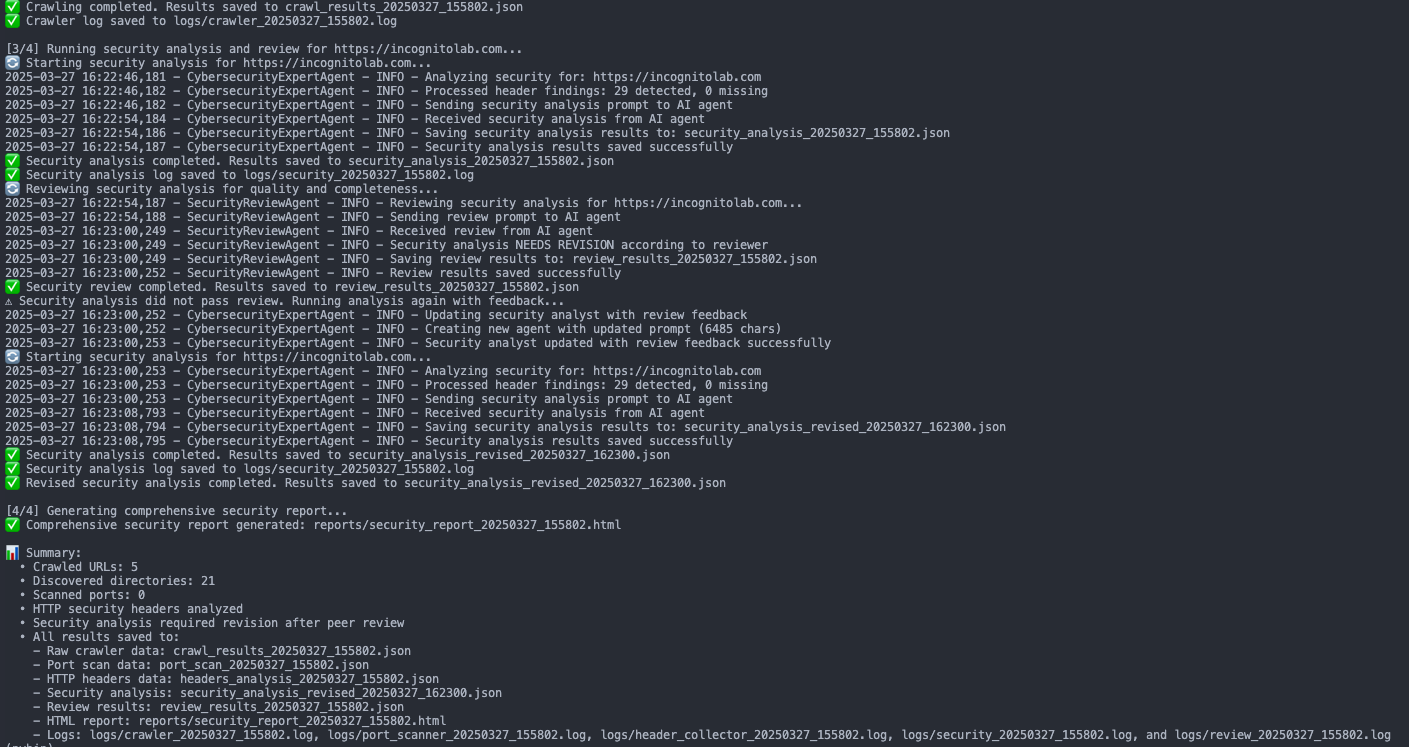
การแก้ไข output ในส่วนของ Directory Enumeration เป็นไปได้ด้วยดี
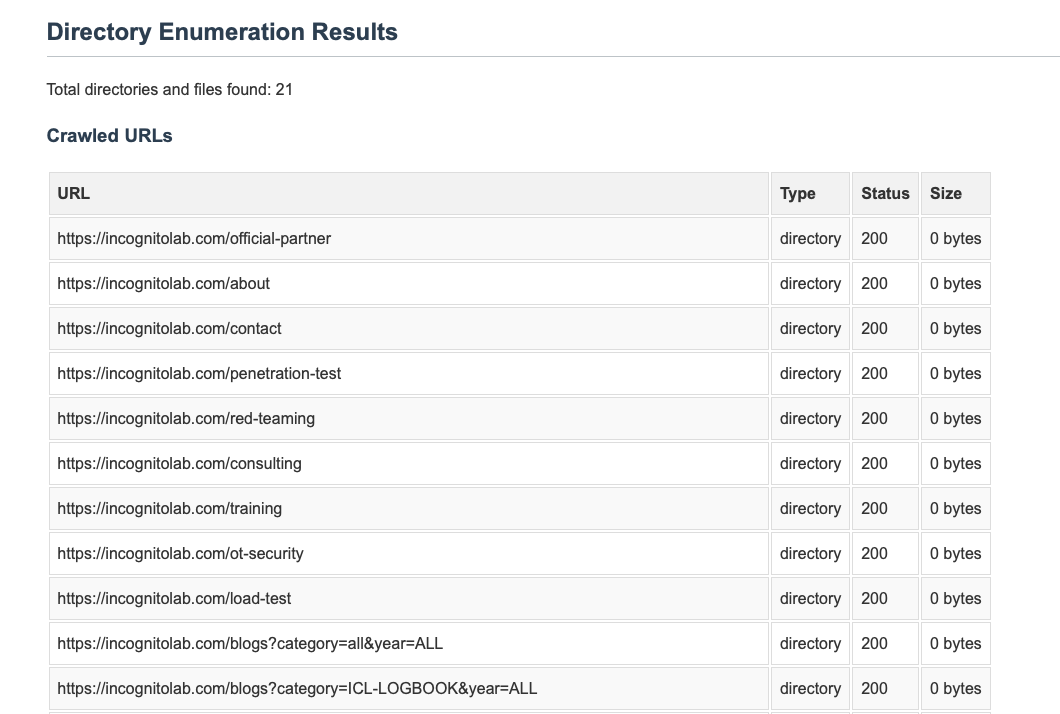

ในส่วนของบทวิเคราะห์ที่ใช้ Agentic AI 2 ตัวในการแก้ไขและวิเคราะห์ร่วมกัน โดยใช้ CVSS ในการประเมินพบว่า AI สามารถประเมินความเสี่ยงได้ดีขึ้นและมีหลักการชัดเจนมากขึ้น
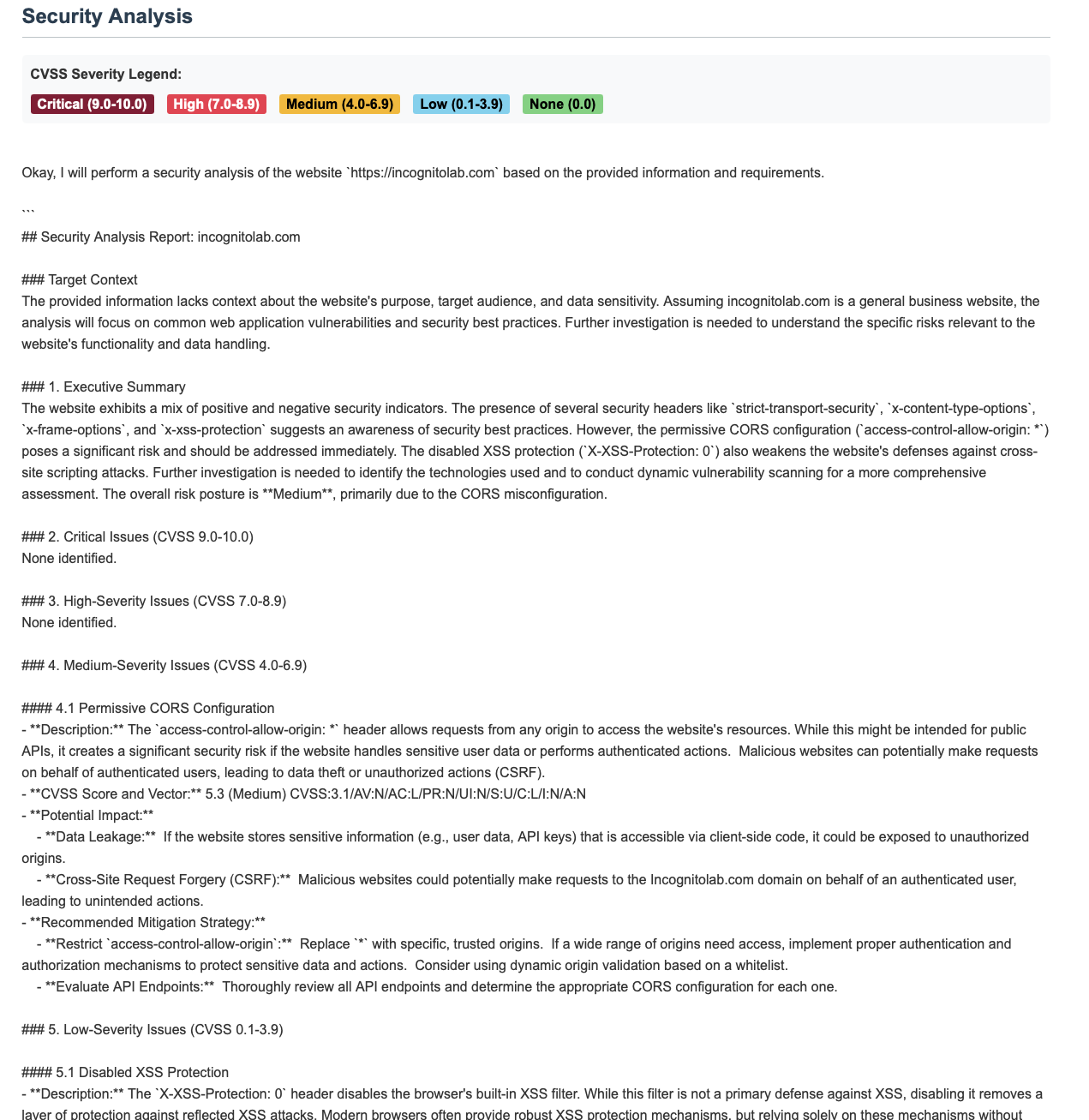
Final Actions
สุดท้ายเราได้นำผลลัพธ์มาปรับปรุงการแสดงผลใหม่ โดยให้ Agentic AI รับข้อมูลจาก review agent มาสร้างเป็น dashboard พร้อมสรุปผลที่สวยงาม และแสดงในรูปแบบ markdown
การปรับปรุงนี้ช่วยให้ผู้ใช้งานสามารถอ่านและทำความเข้าใจรายงานได้ง่ายขึ้น
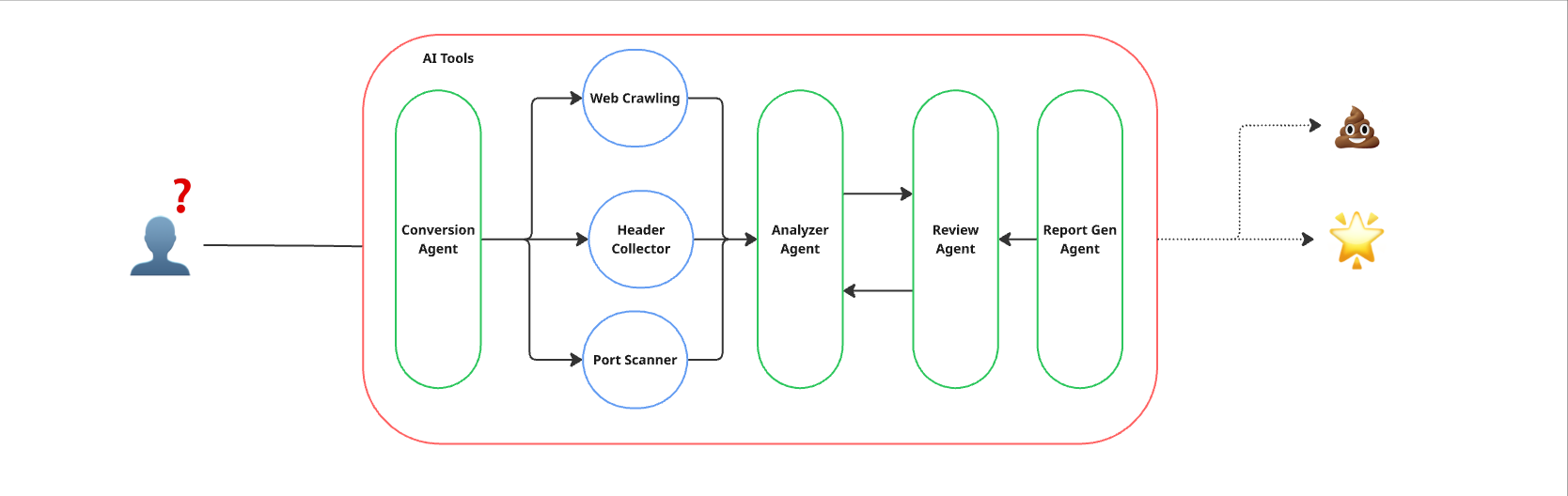
โดยผลลัพท์หน้าตาประมาณนี้ครับ
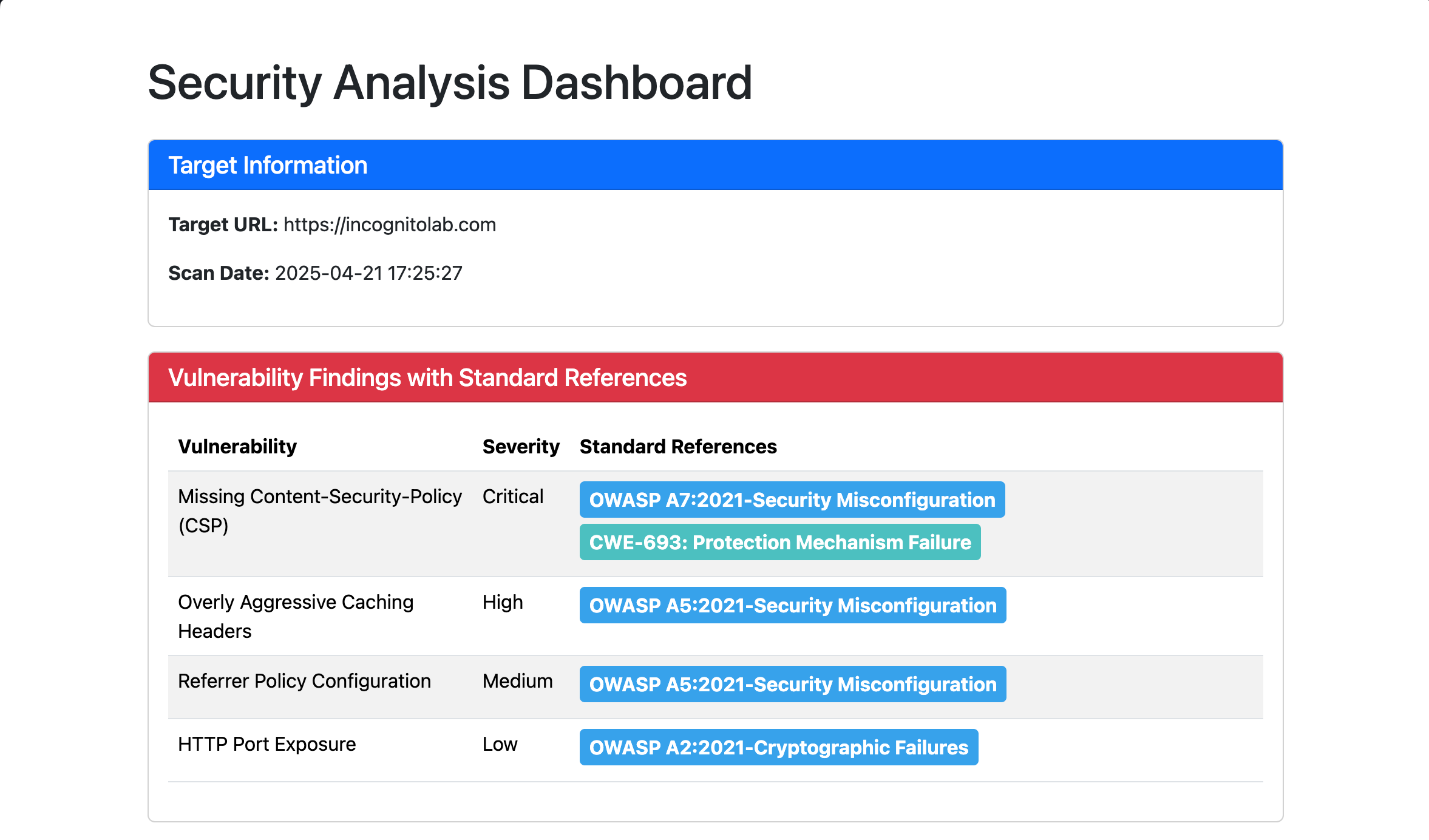
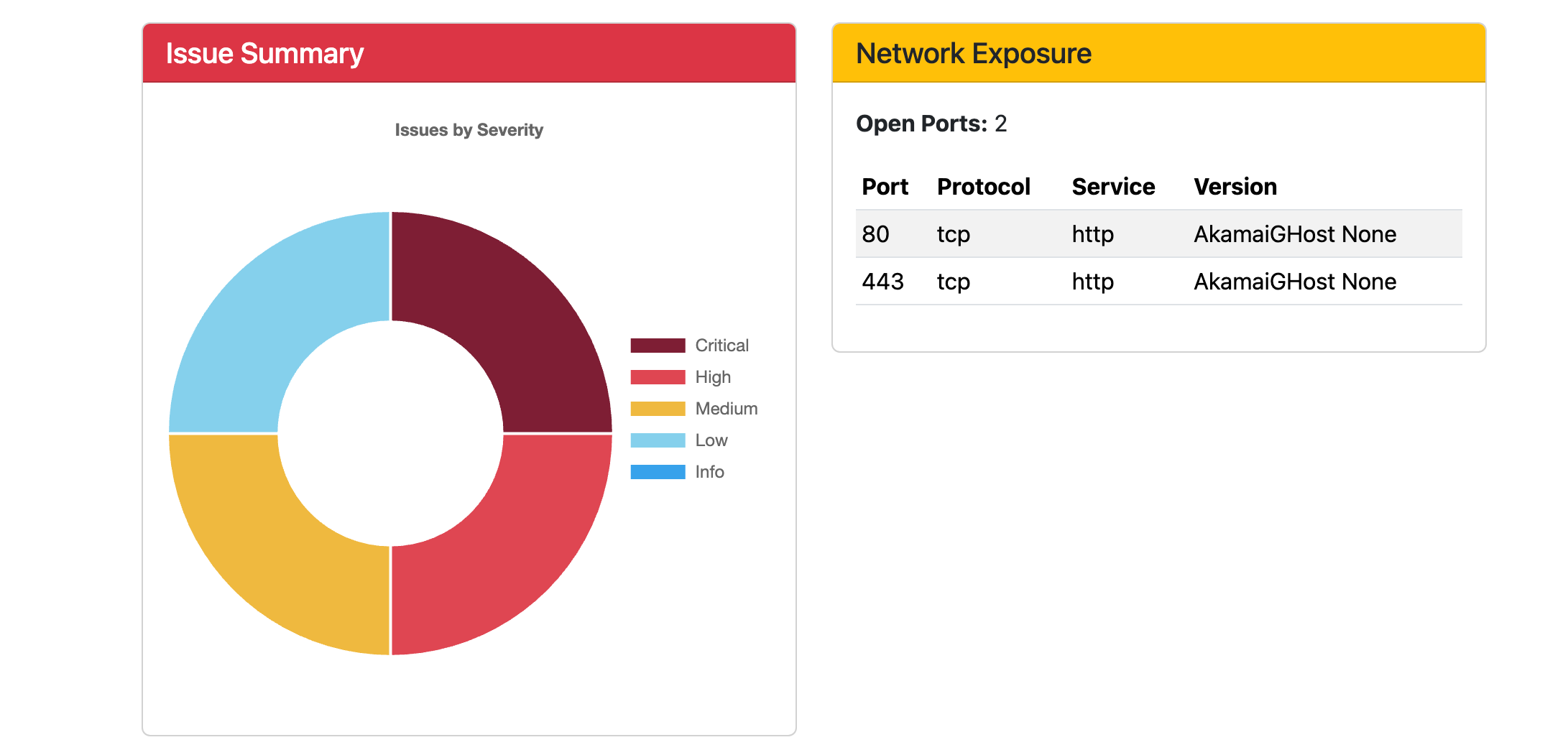

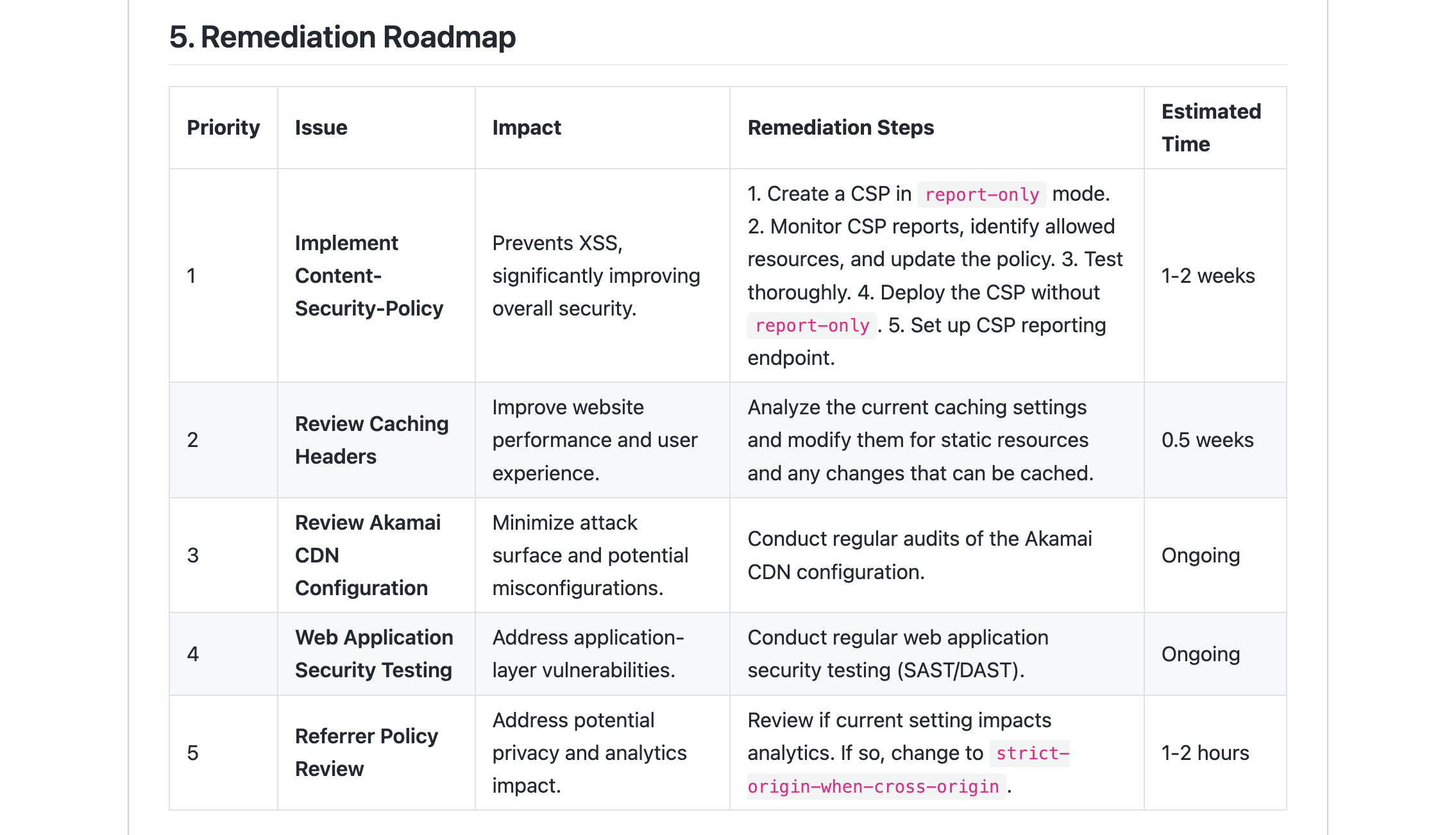
What Next
ในบทความต่อไป เราจะพัฒนา tool ของเราให้แข็งแกร่งขึ้นด้วย web application scan และ VA tool เพื่อให้ได้ผลลัพธ์ที่ครอบคลุมเทียบเท่าเครื่องมือ automated testing ทั่วไป นอกจากนี้ เราจะเพิ่ม agentic AI เข้าไปเพื่อให้เข้าใจ business logic ของเว็บไซต์เป้าหมายได้ดียิ่งขึ้น
Summary
สุดท้ายนี้ การใช้ Agentic AI ในงานด้าน Cybersecurity ได้แสดงให้เห็นถึงการทำงานที่น่าสนใจ โดยเริ่มจากการเก็บข้อมูลพื้นฐาน เช่น URL, Path, Service Port และ HTTP Security Header ด้วยเครื่องมืออย่าง Web Crawling, Directory Brute Force และ Nmap พร้อมทั้งการพัฒนา Agentic AI ที่สามารถวิเคราะห์ข้อมูลเพื่อค้นหา attack surface และช่องโหว่ที่อาจเกิดขึ้น
แม้ว่าการทดสอบจะพบข้อผิดพลาด เช่น การตรวจจับข้อมูลที่ไม่ครบถ้วนและการวิเคราะห์ที่ยังไม่แม่นยำ แต่ก็แสดงให้เห็นศักยภาพของ AI ในการช่วยลดภาระงานและพัฒนาการวิเคราะห์ด้านความปลอดภัย อย่างไรก็ตาม ยังจำเป็นต้องปรับปรุงเครื่องมือและกระบวนการเพิ่มเติมเพื่อให้เหมาะสมกับการใช้งานจริง
สำหรับการนำไปใช้งานจริง จำเป็นต้องนำโมเดลมา fine-tuning และกำหนดกรอบการใช้งานให้ชัดเจนยิ่งขึ้น
หากสนใจเนื้อหาเพิ่มเติมในแนวนี้ สามารถติดตาม incognitolab ได้เลยครับ
OUR SERVICES
PENETRATION TEST
With our high-ethical, professional certified team and methodology based on NIST SP800-115, we offer a full range of cost-effective services to identify your cyber risks in application, infrastructure, and mobile platforms to meet the requirements of your organisation.
Up Next

ARTICLES
Jul
17
2026
Wiper Attack Hospital
เมื่อวันที่ 11 มีนาคม 2569 กลุ่มแฮกเกอร์ Handala ซึ่งเชื่อมโยงกับรัฐบาลอิหร่าน ได้โจมตี บริษัท Stryker ซึ่งเป็นบริษัทผลิตอุปกรณ์การแพทย์ระดับโลกสัญชาติสหรัฐฯ Wiper Attack
READ MORE

ARTICLES
Jul
06
2026
VA/Pentest Service การลงทุนที่คุ้มค่าสำหรับธุรกิจในยุคดิจิทัล
ในทุกวันที่ยุคดิจิทัลเคลื่อนไปข้างหน้าอย่างไม่รีรอและการโจมตีทางไซเบอร์เพิ่มมากขึ้นในทุกวัน อย่าปล่อยให้แฮกเกอร์เป็นผู้พบช่องโหว่บนระบบของคุณก่อนมันจะสายเกินแก้!
READ MORE

ARTICLES
Jul
03
2026
เมื่อ Scammer ไม่ได้หลอกแค่เหยื่อ !!!: เบื้องหลังเทคนิคที่ใช้หลอกคน หลอก Google และหลอกระบบตรวจจับ
ในอดีต การหลอกลวงออนไลน์มักอาศัยอีเมลปลอม SMS ปลอม หรือเว็บไซต์ที่ เลียนแบบองค์กรที่มีชื่อเสียง แต่ในปัจจุบัน…
READ MORE
